De implicaties van grote taalmodellen in fysieke beveiliging
AI (kunstmatige intelligentie) biedt grote mogelijkheden om werkzaamheden te automatiseren en kosten te besparen. Maar is AI wel veilig? Ontdek hoe kunstmatige intelligentie zich vandaag de dag ontwikkelt in onze sector.

De wereld is vandaag de dag helemaal veroverd door grote taalmodellen (LLM's). Slechts enkele maanden nadat OpenAI zijn AI-chatbot ChatGPT introduceerde, had het programma al meer dan 100 miljoen gebruikers. Dit maakt ChatGPT de snelstgroeiende consumententoepassing ooit.
Dat is ook niet zo gek: LLM's kunnen namelijk vragen beantwoorden, complexe onderwerpen uitleggen, volledige filmscripts maken en zelfs code schrijven. Hierdoor raken mensen tegelijkertijd enthousiast van en bezorgd om de mogelijkheden die deze AI-technologie kan bieden.
Hoewel LLM's vooral vandaag de dag een veelbesproken onderwerp zijn, is deze technologie helemaal niet gloednieuw. LLM's en AI-hulpmiddelen kunnen dankzij de vooruitgangen die geboekt worden, nieuwe deuren openen om verscheidene taken te automatiseren. Een goed begrip van de beperkingen en mogelijke risico's van AI is van essentieel belang.
De terminologie verklaren
Wat is nou het verschil tussen kunstmatige intelligentie, machine-learning en deep-learning? En hoe passen grote taalmodellen hierin?
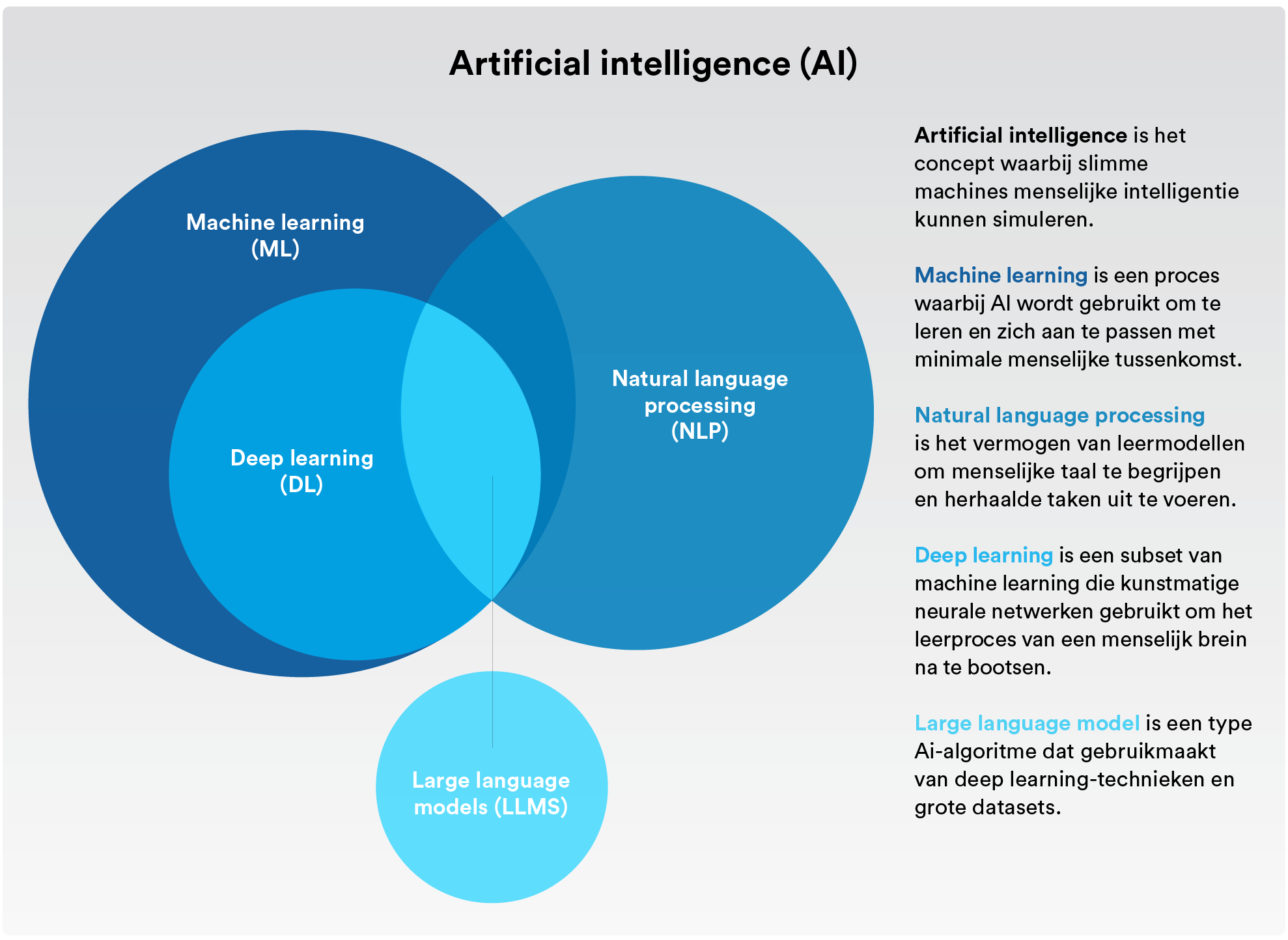
Kunstmatige intelligentie (AI)
Het concept van machines die menselijke intelligentie simuleren. Om een lang verhaal kort te maken: zowel machine-learning als deep-learning vallen allebei onder de categorie kunstmatige intelligentie.
Machine-learning
Kunstmatige intelligentie die zich automatisch kan aanpassen zonder al te veel menselijk ingrijpen.
Natuurlijke taalverwerking
Het proces waarbij kunstmatige intelligentie en machine-learning gebruikt worden om menselijke taal te begrijpen en automatisch repetitieve taken uit te voeren zoals spellingscontroles, vertalingen en samenvattingen.
Deep-learning
Een onderdeel van machine-learning dat gebruikmaakt van kunstmatige neurale netwerken die het leerproces van het menselijke brein nabootsen.
Groot taalmodel
Een AI-algoritme dat deep-learningtechnieken gebruikt en enorm veel informatie van het internet wordt gevoerd.
Wat zijn de risico's van grote taalmodellen?
Eerder dit jaar gaf Sam Altman, CEO van OpenAI, toe dat het programma tekortkomingen had en gevoelig was voor vooroordelen, waardoor de veiligheid van ChatGPT in twijfel werd getrokken. Later ontdekten onderzoekers dat als een groot taalmodel een identiteit kreeg toegewezen als 'slecht persoon' of zelfs bepaalde historische figuren, er tot wel zes keer meer schadelijke reacties werden gegenereerd door het machine-learningmodel.
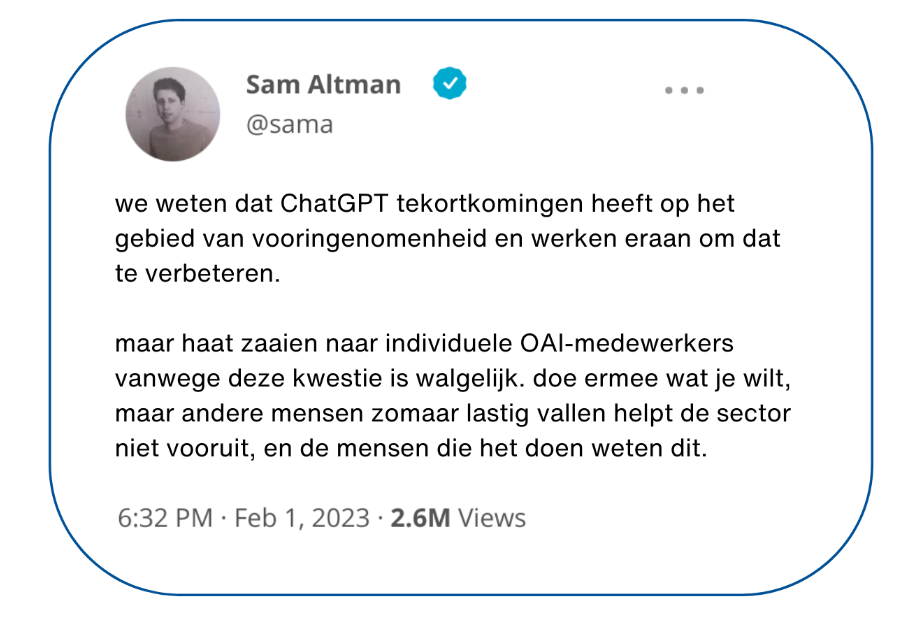
Zijn grote taalmodellen veilig? Bij het afwegen van de risico's van LLM's, moet u altijd in uw achterhoofd houden dat ze getraind zijn om de gebruiker voorop te zetten en deze tevreden te stellen. LLM's maken bovendien gebruik van een onbeheerde AI-trainingsmethode om informatie te vergaren uit een grote verzameling van willekeurige data op het internet. Dit betekent dat de antwoorden die ze geven niet altijd nauwkeurig, waarheidsgetrouw of onbevooroordeeld zijn. Dit alles wordt extreem gevaarlijk in een beveiligingscontext.
Sterker nog, vanwege deze onbeheerde AI-methode is de term 'waarheidshallucinaties' de wereld in geholpen. Dit gebeurt wanneer een AI-model antwoorden genereert die geloofwaardig lijken, maar niet feitelijk zijn of gebaseerd zijn op data uit de echte wereld.
Het gebruik van LLM's kan ook ernstige privacy- en vertrouwelijkheidsrisico's met zich meebrengen. Het model kan namelijk leren van data die vertrouwelijke informatie bevatten van personen en bedrijven. En aangezien elke tekstprompt gebruikt wordt om de volgende versie te trainen, kan iemand die de LLM vragen stelt over vergelijkbare inhoud bekend raken met deze gevoelige informatie via antwoorden van de AI-chatbot.
Bovendien kan deze AI-technologie ook voor kwaadwillige doeleinden worden gebruikt. Kwaadwillenden die weinig of geen ervaring hebben met programmeren zouden bijvoorbeeld een AI-chatbot kunnen vragen om een script te schrijven dat een bekende kwetsbaarheid misbruikt of een lijst aanvragen met manieren om specifieke toepassingen en protocollen te hacken. Dit zijn weliswaar hypothetische voorbeelden, maar dat neemt niet weg dat er misschien manieren zijn die we nog niet kunnen voorzien waarop deze technologieën misbruikt kunnen worden.
Hoe ontwikkelen grote taalmodellen zich in de sector van fysieke beveiliging?
Nu LLM's een grote rage beginnen te worden, is er langzaam het idee ontstaan dat AI op magische wijze alles mogelijk kan maken. Maar niet alle AI-modellen zijn exact hetzelfde of ontwikkelen zich op hetzelfde tempo.
Grote taal-, deep-learning- en machine-learningmodellen leveren uitkomsten op basis van waarschijnlijkheid. Laten we specifiek grote taalmodellen onder de loep nemen: hun doel is om het meest waarschijnlijke antwoord te formuleren op basis van een massale, ongedifferentieerde hoeveelheid data. Zoals eerder vermeld, kan dit leiden tot onjuiste informatie of AI-hallucinaties.
Op het gebied van fysieke beveiliging maken machine-learning- en deep-learningalgoritmen geen gebruik van generatieve AI, die informatie kan verzinnen. In plaats daarvan worden AI-modellen ontworpen om patronen te herkennen en om data te classificeren. Aangezien deze uitkomsten nog steeds gebaseerd zijn op waarschijnlijkheid, moeten mensen op bepaalde punten toch ingrijpen en beslissen wat uiteindelijk waar is of niet.
Dit geldt ook voor de gunstige resultaten van LLM's. Wat beveiligingstoepassingen betreft: het kan zijn dat operators in de toekomst gebruik kunnen maken van een AI-taalmodel binnen een beveiligingsplatform om snel antwoorden te krijgen op vragen als "Hoeveel personen bevinden zich op dit moment op de 3e verdieping?" of "Hoeveel bezoekersbadges hebben we de afgelopen maand uitgedeeld?" Organisaties kunnen bovendien aan de hand van een AI-taalmodel beveiligingsbeleidsregels maken of details in antwoordprotocols verbeteren.
Het maakt niet uit hoe AI-taalmodellen worden gebruikt, één ding is zeker: voor beveiligingsdoeleinden zijn benaderingen nodig waarbij de modellen in een meer gesloten omgeving worden uitgevoerd. Dus hoewel veel mensen nu erg enthousiast zijn over LLM's, moet er nog steeds veel aan ze gesleuteld worden voordat ze echt veilig en geschikt zijn voor toepassingen in fysieke beveiliging.
Hoe wordt AI geïmplementeerd in fysieke beveiligingsomgevingen?
LLM's zijn nu misschien de belangrijkste trend, maar het gebruik van AI bij fysieke beveiliging is niet nieuw. Er zijn veel interessante manieren waarop AI wordt gebruikt om verschillende toepassingen te ondersteunen.
Hier volgen enkele voorbeelden van hoe AI vandaag de dag wordt gebruikt in fysieke beveiliging:
Onderzoek versnellen
Video's van een specifieke periode onderzoeken om alle beelden met een rood voertuig te vinden.
Mensen tellen automatiseren
Een waarschuwing krijgen bij een maximale bezettingsgraad in een gebouw of weten wanneer de rijen voor klanten te lang worden om de service te verbeteren.
Kentekenplaten van voertuigen detecteren
Het volgen van verdachte voertuigen, het stroomlijnen van het parkeren van werknemers bij kantoren of het monitoren van verkeersstromen in een stad.
Cybersecurity verbeteren
Het verbeteren van antivirusbescherming op apparaten door machine learning te gebruiken om bekende en onbekende malware te identificeren en te blokkeren.
Voor de meeste bedrijven komt de implementatie van AI vooral neer op een paar drijvende factoren, namelijk de mogelijkheid om data-analyses uit te voeren op een grote schaal en hogere maten van automatisering bereiken. In een tijdperk waarin iedereen het heeft over digitale transformatie, willen organisaties profiteren van hun investeringen in fysieke beveiliging en data om productiviteit te verhogen, bedrijfsvoering te verbeteren en kosten te verminderen.
Automatisering kan organisaties helpen om te voldoen aan verschillende industrienormen en voorschriften, terwijl de kosten van naleving worden verlaagd. Dat komt omdat deep-learning en machine-learning de mogelijkheid bieden om een groot deel van dataverwerking en workflows te automatiseren terwijl ze operators relevante inzichten bieden. Hierdoor kunnen ze snel reageren op bedrijfsstoringen en betere beslissingen nemen.
En hoewel AI steeds meer gedemocratiseerd wordt door verschillende oplossingen voor videoanalyse, zijn er nog steeds veel mythes over wat AI wel en niet kan doen. Het is dus belangrijk dat professionals begrijpen dat de meeste AI-systemen geen pasklare oplossing bieden voor fysieke beveiliging.
Het automatiseren van taken of het bereiken van een gewenst resultaat is een proces dat bestaat uit het bepalen van technische uitvoerbaarheid. Dit omvat het identificeren van bestaande oplossingen die al geïmplementeerd zijn, andere technologieën die misschien nodig zijn en eventuele compatibiliteitsproblemen of andere omgevingsfactoren waar rekening mee gehouden moet worden.
Zelfs wanneer de uitvoerbaarheid is beoordeeld, kunnen sommige organisaties zich afvragen of de investering het resultaat rechtvaardigt. Dus hoewel de AI van essentieel belang is voor het bereiken van een hogere mate van automatisering in de sector voor fysieke beveiliging, moet er nog veel afgewogen, doorgedacht en gepland worden om nauwkeurige resultaten te bereiken.
Met andere woorden: het is van cruciaal belang dat nieuwe AI-oplossingen voorzichtig verkend worden en dat hun beloofde uitkomsten met een korreltje zout genomen worden.
Wat zijn de beste manieren om vandaag de dag te profiteren van AI bij fysieke beveiliging?
AI-toepassingen ontwikkelen zich op nieuwe en spannende manieren. Naar verwachting kunnen ze bedrijven helpen om specifieke uitkomsten te behalen die productiviteit, beveiliging en veiligheid verbeteren voor de hele organisatie.
Een van de beste manieren om te profiteren van nieuwe AI-ontwikkelingen in fysieke beveiliging is door een open beveiligingsplatform te implementeren. Met een open structuur krijgen beveiligingsprofessionals de vrijheid om AI-toepassingen te verkennen die meer waarde kunnen opleveren voor hun bedrijfsvoering. Naarmate AI-oplossingen op de markt komen, kunnen leiders deze toepassingen (vaak gratis) uitproberen en vervolgens selecteren welke het beste bij hun doelstellingen en omgevingen passen.

Maar naarmate er nieuwe kansen ontstaan, ontstaan er ook nieuwe risico's. Daarom is het net zo belangrijk dat u samenwerkt met organisaties die databescherming, privacy en verantwoord gebruik van AI prioriteren. Dit helpt niet alleen de digitale bestendigheid te vergroten en het vertrouwen in uw bedrijf te verbeteren, maar het is ook onderdeel van sociale verantwoordelijkheid.
Uit het IBM-rapport AI Ethics in Action bleek dat 85% van de consumenten het belangrijk vindt dat organisaties rekening houden met ethiek wanneer ze ervoor kiezen om AI toe te passen bij het aanpakken van maatschappelijke problemen. 75% van de leidinggevenden gelooft dat een goede AI-ethiek een bedrijf kan onderscheiden van de concurrentie. En meer dan 60% van de leidinggevenden gelooft dat AI-ethiek hun organisaties kan helpen om beter te presteren op het gebied van diversiteit, inclusiviteit, sociale verantwoordelijkheid en duurzaamheid.
Hoe Genetec rekening houdt met privacy en databeheer aan de hand van verantwoorde AI
Aangezien AI-algoritmen grote hoeveelheden data snel en nauwkeurig kunnen verwerken, is AI gestaag een belangrijk hulpmiddel voor fysiekebeveiligingsoplossingen aan het worden. Maar naarmate AI zich verder ontwikkelt, neemt het risico dat persoonlijke informatie op een privacyschendende manier gebruikt wordt toe.
AI-modellen kunnen bovendien per abuis onjuiste beslissingen produceren of resultaten geven die gebaseerd zijn op allerlei vooroordelen. Dit kan beslissingen beïnvloeden en uiteindelijk zelfs leiden tot discriminatoire situaties. Hoewel AI de revolutionaire kracht heeft om te beïnvloeden hoe werk wordt gedaan en hoe beslissingen worden genomen, moeten de oplossingen verantwoord geïmplementeerd worden.
Daarom neemt ons Genetec™-team verantwoorde AI zeer serieus. Sterker nog, we hebben een aantal richtlijnen opgesteld voor het maken, verbeteren en onderhouden van onze AI-modellen. Voor deze richtlijnen houden we de volgende drie categorieën aan:
 Privacy en databeheer
Privacy en databeheer
Als technologieleverancier zijn wij verantwoordelijk voor hoe we AI toepassen bij het ontwikkelen van onze oplossingen. Dat houdt in dat we alleen datasets gebruiken die voldoen aan de relevante databeschermingsvoorschriften. Waar mogelijk anonimiseren wij zelfs datasets en maken we gebruik van synthetische data. We behandelen datasets bovendien uiterst zorgvuldig en houden databescherming en privacy altijd hoog in het vaandel.

Dit houdt ook in dat we ons houden aan strikte autorisatie- en authenticatiemaatregelen om ervoor te zorgen dat gevoelige data en informatie uit onze AI-toepassingen nooit in de verkeerde handen vallen. Wij streven ernaar om onze klanten te voorzien van ingebouwde hulpmiddelen waarmee ze beter de voortdurend ontwikkelende AI-voorschriften kunnen naleven.
 Transparantie en eerlijkheid
Transparantie en eerlijkheid
Tijdens de ontwikkeling en het gebruik van AI-modellen, denken we altijd na over hoe we vooroordelen kunnen minimaliseren. Ons doel is om ervoor te zorgen dat onze oplossingen altijd resultaten opleveren die gebalanceerd en rechtvaardig zijn. Om deze resultaten te waarborgen, testen we onze AI-modellen rigoreus voordat we ze delen met onze klanten. Bovendien doen we ons uiterste best om de nauwkeurigheid van en het vertrouwen in onze modellen te verbeteren. Tot slot

willen wij onze AI-modellen transparant maken. Dit houdt in dat we onze klanten exact kunnen uitleggen hoe onze AI-algoritmen tot een bepaalde beslissing of uitkomst zijn gekomen.
 Mensgestuurde beslissingen
Mensgestuurde beslissingen
Bij Genetec zorgen wij ervoor dat onze AI-modellen niet zelfstandig cruciale beslissingen kunnen nemen. Wij vinden dat er altijd een mens betrokken moet zijn bij het proces en de uiteindelijke beslissing moet nemen. Binnen de context van fysieke beveiliging is het van essentieel belang dat beslissingen gericht worden op de mens. Denk aan levensbelangrijke situaties waarin mensen zich van nature bewust zijn van gevaren en de juiste acties kunnen nemen om een leven te redden. Machines kunnen de nuances van een gebeurtenis in het echte leven niet aanvoelen zoals een

beveiligingsoperator, dus het is geen goed idee om alleen maar te vertrouwen op statische modellen. Dit is ook de reden dat we de output van AI-modellen zodanig willen presenteren dat een mens de meest weloverwogen beslissingen kan nemen. AI kan inzichten bieden, maar mensen moeten altijd de besluitvormers zijn.
