大規模言語モデルがフィジカルセキュリティに与える影響
AIを活用することで自動化とコスト削減の可能性が大きく広がります。しかし、AIは安全に利用できるのでしょうか? 現在、人工知能が業界でどのように進化しているかをご覧ください。

近年、大規模言語モデル (LLM) は世界で話題になっています。OpenAIが人工知能(AI)チャットボットであるChatGPTは、リリース後わずか数か月でユーザー数1億人を突破し、史上最速で成長している消費者向けアプリケーションとなりました。
これは驚くべきことではありません。LLMを利用すると、質問への応答や複雑なトピックの解説から、ノーカット版の映画の脚本の作成やコードの生成まで、あらゆることが可能です。このようなLLMの進化により、世界中の人がAIテクノロジーの機能に期待と同時に不安も抱くようになりました。
LLMが注目されるようになったのは最近ですが、このテクノロジーが長く存在することは注目に値します。テクノロジーは進化していますが、LLMや他のAIツールを利用することで、さまざまなタスクでさらに高度な自動化を実現する新しい可能性が生まれています。AIの限界と潜在的なリスクを根本的に理解することは不可欠です。
用語の明確化
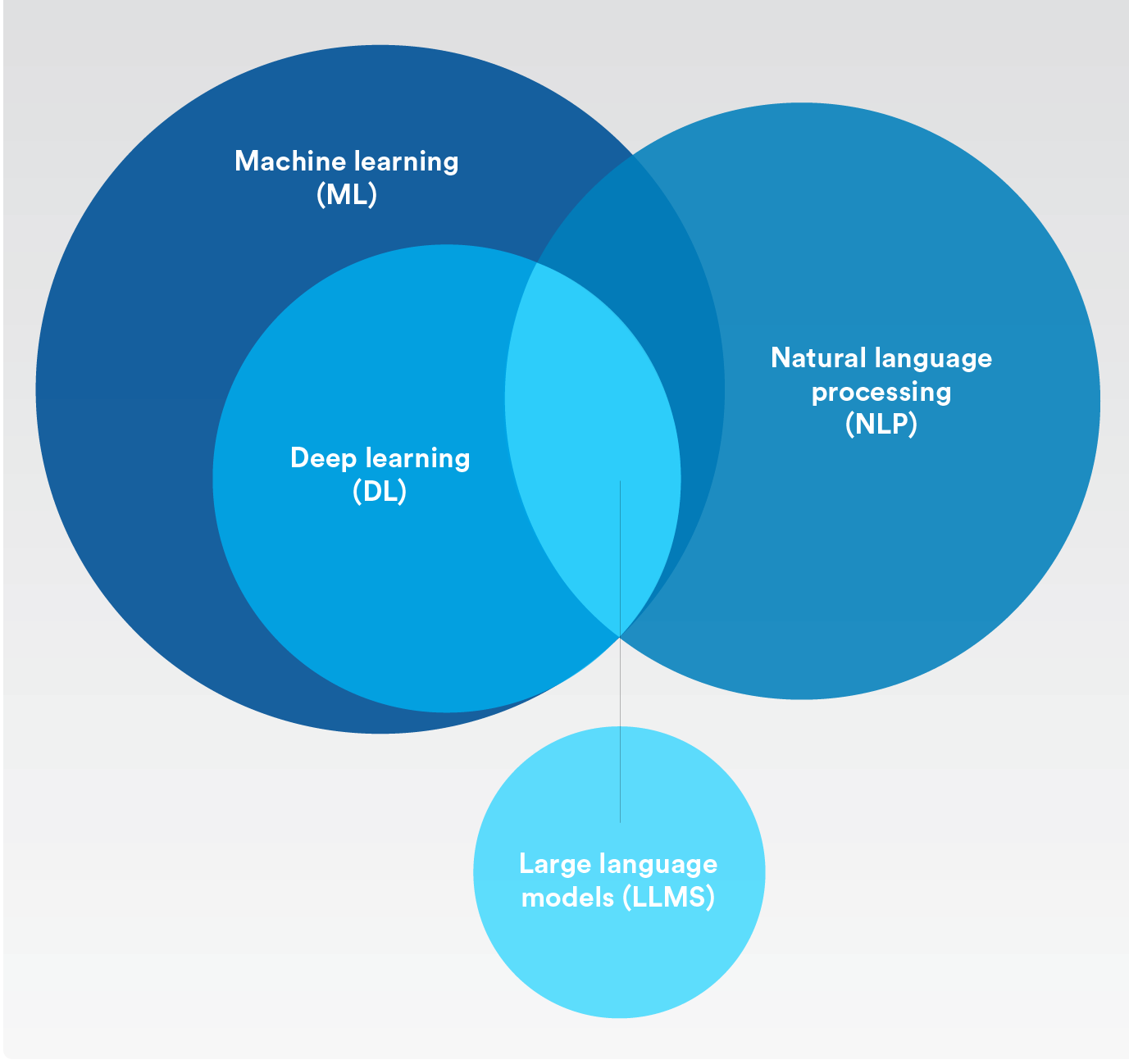
人工知能、機械学習、深層学習の違い大規模言語モデルの分類
人工知能 (AI)
人工知能
機械によって人間の知能プロセスをシミュレーションするという概念。一言で言えば、機械学習とディープラーニングはどちらも人工知能のカテゴリーに入る。
機械学習
人間による操作を必要とすることなく自動的に適応できる人工知能。
自然言語処理
人工知能と機械学習を用いて人間の言語を理解し、スペルチェック、翻訳、要約などの反復的なタスクを自動的に実行するプロセス。
深層学習
人工の神経ネットワークを用い、人間の脳の学習プロセスを模倣する機械学習のサブセット。
大規模言語モデル
深層学習技術を用いて、インターネットから大量の情報を得る人工知能アルゴリズム。
大規模言語モデルのリスクとは?
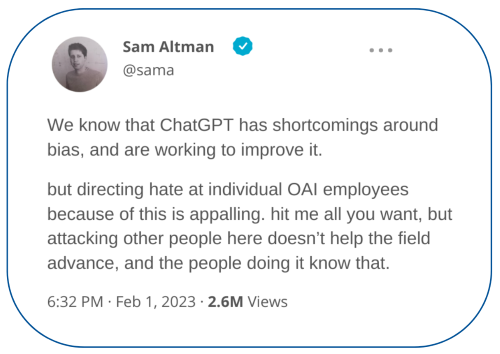
今年の初め、OpenAIのCEOであるSam Altmanは、ChatGPTのセキュリティに疑問が提起される原因となった、バイアスに関する欠陥を認めました。最近、研究者らは、「悪い人」や特定の歴史上の人物などのアイデンティティを大規模言語モデルに学習させると、機械学習モデルから生成される有毒または有害な回答が6倍に増加することを発見しました。
大規模言語モデルは安全か? LLMのリスクを比較検討するときには、大規模言語モデルはユーザーを満足させることを最優先に訓練されるという点を考慮することが重要です。また、LLMは無監督AI学習方法を用いて、インターネットから大量の無作為データを収集します。つまり、収集した回答が必ずしも正確、真実、または偏見がないとは限らないことを意味します。セキュリティコンテキストの場合は極めて危険です。
実際、この無監督AI学習方法は、現在「真実の幻覚」という課題に直面しています。この幻覚は、AIモデルがもっともらしく見えるが、事実ではない、または実際のデータに基づいていない回答を生成する場合に発生します。
LLMを用いると、深刻なプライバシーおよび機密情報のリスクが生じる可能性もあります。このモデルは、人や企業に関する機密情報を含むデータを使って学習する場合があるからです。また、すべてのテキストプロンプトは次のバージョンのトレーニングに使用されるため、同様のコンテンツについてLLMにプロンプトを表示した場合、AIチャットボットの回答を通じてその機密情報が洩れる可能性があります。
さらに、このAIテクノロジーを悪意のある人に悪用される場合があります。プログラミングの知識がほとんどない、あるいはまったくない悪意のある個人が、AIチャットボットに既知の脆弱性を悪用するスクリプトを書かせたり、特定のアプリケーションやプロトコルをハッキングする方法のリストを要求したりすることを考えてみよう。これらは架空の例ですが、このテクノロジーを用いれば、予想できないような方法で悪用される可能性があることがわかります。
大規模言語モデルはフィジカルセキュリティの分野でどのように進化しているのか。
現在、大規模言語モデル (LLM) は注目を集め、AIは魔法のように何でも可能にできると思われています。しかし、すべてのAIモデルが同じである、または同じペースで進化しているわけではありません。
大規模言語、深層学習、機械学習モデルは、確率に基づいて結果を生成します。大規模言語モデルを詳しく見てみると、主な目標は、無差別に収集した大量のデータから最も妥当な回答を生成することです。前述のように、これは誤報やAI幻覚につながる可能性があります。
フィジカルセキュリティの分野では、機械学習と深層学習のアルゴリズムは、情報を発明できる生成AIに依存するものではありません。その代わりにAI モデルを構築し、パターンを検出してデータを分類できるようにします。結果は依然として確率に基づき生成されるため、人間がプロセスに関与し、何が真実で何が真実でないかの最終的な判断をする必要があります。
LLMが生成する有益な結果のすべてについても同じことが言えます。セキュリティアプリケーションに用いる場合、将来的には、オペレータがセキュリティプラットフォーム内のAI言語モデルを用いて、「現在3階には何人いますか?」や「先月は何人の訪問者入館証を発行しましたか?」などの回答を迅速に得られる可能性があります。また、組織がセキュリティポリシーを作成したり、応答プロトコルの詳細を改善したりするためにも使用できます。
AI言語モデルをどのように用いるかに関係なく、セキュリティのユースケースには、より密接な環境で言語モデルを実行する場合のアプローチ方法が必要になることは確かです。現在、LLMは注目されていますが、フィジカルセキュリティのアプリケーションで安全かつ実用的に使用できるようになるまでには、まだ多くの課題が残っています。
AIはフィジカルセキュリティ分野でどのように実装されているのか。
今、LLMは注目されていますが、フィジカルセキュリティにAIを使用することは目新しいことではありません。さまざまなアプリケーションにAIを使用する方法は多数あります。
今日のフィジカルセキュリティでAIがどのように使用されているかの例をいくつか紹介します。
調査の迅速化
特定期間の動画を精査して、赤い車両が映った映像を見つける。
人数カウントの自動化
建物内の最大収容数のしきい値に近づいた場合に警戒する、または顧客の待ち列が長くなったためサービスを強化できない状態を把握する。
車両ナンバープレートの検出
指名手配車両の追跡、オフィスにおける従業員の駐車の流れの合理化、または都市全体の交通量の流れの監視。
サイバーセキュリティの強化
機械学習を用いてエンドポイントで実行される既知および未知のマルウェアを特定し、阻止することで、アプライアンスのウイルス対策保護を強化。
ほとんどの企業の場合、AIの実装は大規模なデータ分析とさらに高度な自動化を実現させる要因によって異なります。誰もがデジタルトランスフォーメーションに注目する時代において、組織はフィジカルセキュリティへの投資とデータを活用して、生産性を高め、運用を改善し、コストを削減したいと考えています。
自動化によって、組織はコンプライアンスにかかるコストを削減し、さまざまな業界標準や規制に準拠することもできます。深層学習および機械学習によって、オペレータは関連するインサイトを得られると同時に、多くのデータ処理とワークフローを自動化できる可能性が生まれるからです。業務が中断した場合に迅速に対応し、より有効な意思決定を下すことができます。
また、さまざまな動画分析ソリューションによってAIの民主化は進んでいますが、依然としてAIには、できることとできないことがあると言われています。よって、専門家は、フィジカルセキュリティに導入するほとんどのAIソリューションが、あらゆる場合に適用できるとは限らないことを理解することが重要です。
タスクを自動化する、または期待した結果を達成することは、技術的に実現可能かどうかを判断するプロセスの一部です。実現可能性を判断する場合には、導入している既存のソリューション、必要になる可能性のある他のテクノロジー、および解決すべき互換性の問題や考慮すべき他の環境要因はないかどうかを見極めます。
実現可能だと分かったとしても、投資が結果につながるのかどうか疑問に思う組織もあるでしょう。よってAIは、フィジカルセキュリティ業界でより高度な自動化を実現するために重要な要素ではありますが、正確な結果を達成するためには、依然として多くの考慮事項、事前の計画、計画立案が必要です。
言い換えれば、新しいAIソリューションを模索する際には十分な注意が必要であり、期待する結果をクリティカル・シンキングやデューデリジェンスを用いて比較検討する必要があります。
現在のフィジカルセキュリティの世界でAIを活用する最良の方法
AI対応アプリケーションは、画期的な形で進化しています。組織全体で生産性、セキュリティ、安全性を高めるという特定の結果を達成させる上で大いに期待されています。
フィジカルセキュリティにおける新しいAIの進歩を活用する最良の方法の1つは、オープンセキュリティプラットフォームを実装することです。セキュリティの専門家は、オープンアーキテクチャを活用することで、運用全体でさらに大きな価値を生み出す人工知能アプリケーションを自由に試すことができます。AIソリューションが発売されると、リーダーはこれらのアプリケーションをほとんどの場合、無料で試すことができ、その上で目的と環境に最適なアプリケーションを選択できます。

新しいチャンスが生まれれば、新しいリスクも出現します。データ保護、プライバシー、責任あるAI の活用を優先する組織と提携することが同じくらい重要なのは、そのためです。これは、サイバーレジリエンスを強化し、ビジネスへの信頼を高めることができるだけでなく、これは社会的責任の一部でもあります。
.IBMのレポート「AI Ethics in Action」によると、AIを活用して社会の問題に取り組む際に、組織は倫理的に検討することが重要であると述べた消費者は85%を占めました。AI倫理を遵守することで、競合他社との差別化を図ることができると考える経営幹部は75%になりました。また、経営幹部の60%以上が、AI 倫理に取り組むことで、ダイバーシティ(多様性)、インクルージョン、社会的責任、持続可能性という側面で組織のパフォーマンスを向上させることができると考えています。
Genetecが、どのようにプライバシーとデータガバナンスを考慮し、責任あるAIの活用に注力しているか
人工知能 (AI) アルゴリズムは大量のデータを迅速かつ正確に処理できるため、AIはフィジカルセキュリティソリューションにとってますます重要なツールになっています。しかし、AIが進化すれば、プライバシー侵害につながり得る手段で個人情報にアクセスできる可能性も拡大します。
AIモデルは、さまざまなバイアスに基づき、誤って歪んだ決定や結果を生成する可能性もあります。これは意思決定に影響を与え、究極的には差別につながる可能性があります。AIには、仕事や意思決定の方法に革命的な変化をもたらす力がありますが、責任を持って導入する必要があります。
Genetec™のチームが責任あるAIの活用に真摯に取り組んでいるのは、そのためです。実際、私たちはAIモデルを作成、改善、維持するための指導原則を考案しました。この指針は次の3つの主要な柱で構成されています。
 プライバシーおよびデータガバナンス
プライバシーおよびデータガバナンス
当社はテクノロジープロバイダーとして、ソリューションの開発にAIをどのように活用するかについて責任を負います。これは、すなわち、関連するデータ保護規制を尊重するデータセットのみを使用することです。また、可能な限り、データセットを匿名化し、合成データを使用しています。また、データセットの取り扱いには細心の注意を払い、すべての活動においてデータ保護とプライバシーを最優先に取り組んでいます。これには、厳しい承認および認証を徹底し、AI主導のアプリケーション全体で不正ユーザーが機密データや情報にアクセスできないようにすることが含まれます。当社は、顧客に内蔵型ツールを提供し、常に変わるAI規制に準拠できるようにすることに尽力しています。
 透明性と公平性
透明性と公平性
当社がAIモデルを開発および使用する際には、バイアスを最小限に抑える方法を常に検討しています。当社の目標は、ソリューションを活用して、常にバランスのとれた公平な結果をもたらすことです。これを実現するために、AIモデルを厳密にテストしてからお客様に提供しています。また、引き続きモデルの精度と信頼性の改善にも取り組みます。最後に、説明可能なAIモデルになるよう努めます。AIアルゴリズムが結果を決定または生成したときに、どのようにその結果にたどりついたかを正確に伝えることができます。
 人間主導の意思決定
人間主導の意思決定
Genetecでは、AIモデルが単独で重要な決定を下すことができないようにしています。当社では、人間が常に決定のプロセスに関与し、最終決定権を持つ必要があると考えています。フィジカルセキュリティの文脈では、人間中心の意思決定を優先することが重要になるからです。人間が本質的に危険を察知し、生きるための行動が求められる生死にかかわる状況を考えてみましょう。機械は、セキュリティオペレータのように実際に発生したイベントの複雑性を把握できないため、統計モデルのみに依存した結果は回答になり得ません。人間が最も多くの情報に基づき選択できる方法で、AIモデルが出力を提示することを常に目指しているのは、そのためでもあります。AIを活用することで洞察は得られますが、意思決定者は常に人間でなければなりません。
